Compute Nodes
Devana is a cluster of compute nodes named n[001-148]. The nodes are equiped with x86-64 architecture Intel processors. It is built using the Lenovo technology and contains four types of compute nodes:
| Nodes | Moda / Cnt | Cores | Memory | Diskb | GPUs | Network |
|---|---|---|---|---|---|---|
| n[001-048] | U / 48 | 64 | 256 GB | 3.84 TB | none | 100 Gb/s |
| n[049-140] | U / 92 | 64 | 256 GB | 1.92 TB | none | 100 Gb/s |
| n[141-144] | A / 4 | 64 | 256 GB | 3.84 TB | 4x A100 | 200 Gb/s |
| n[145-148] | A / 4 | 64 | 256 GB | 3.84 TB | 4x A100 | 200 Gb/s |
a U - universal module, A - accelerated module.
b The value represents raw local disk capacity. Node groups within the same module differ in local disk performance.
Universal module nodes¶

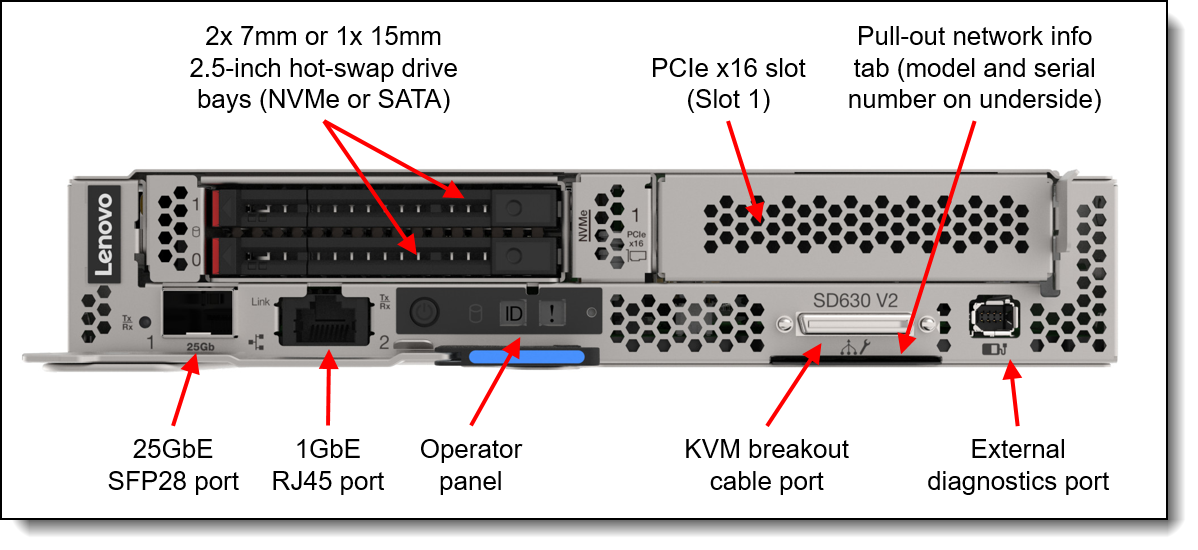
The universal module consists of 140 server units each representing a compute node. The compute node is Lenovo ThinkSystem SD630 V2 dense two-socket server in a 0.5U rack form factor. The solution consists of 35 2U ThinkSystem DA240 enclosures containing four front-access SD630 V2 servers. Each node incorporates two third-generation Intel Xeon Scalable processors (Ice Lake family). There are two groups of compute nodes that differ slightly in local storage performance.
The SD630 V2 is well suited for a variety of workloads ranging from cloud, analytics to AI and high performance computing application like molecular modeling, materials design, computer aided engineering or electronic design automation.
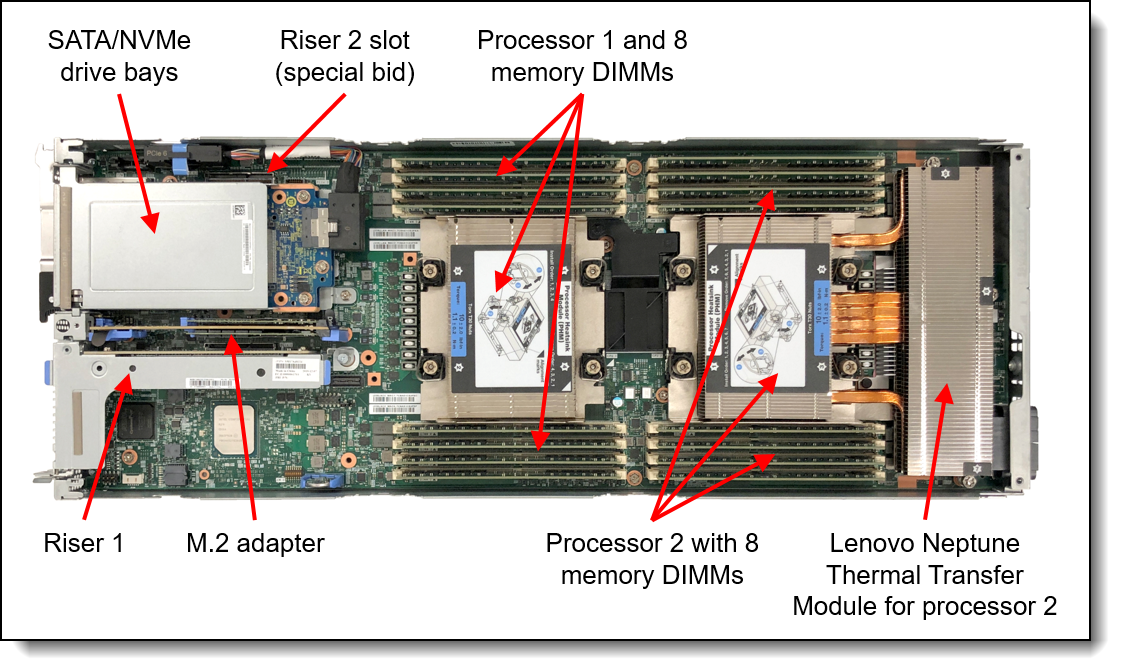
Universal compute node facts:
| Feature | n[001-048] | n[049-140] |
|---|---|---|
| Processora | 2× Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
| RAM | 256 GB DDR4 RAM @ 3200 MHz | |
| Diskb | 3.84 TB NVMe SSD @ 5.8 GB/s, 362 kIOPs | 1.92 TB NVMe SSD @ 2.3 GB/s, 166 kIOPs |
| Network | 200 Gb/s HDR Infiniband | |
| Performancec | ????? GFLOP/s per compute node | |
a 2.00GHz base, 3.2GHz single core.
b Performance data obtained with synthetic fio test. Bandwidth measured at mixed sequential read/write test (ratio 80/20 and 1M block). Operations count measured at mixed random read/write test (ratio 80/20 and 4k block).
c DP.
Accelerated module nodes¶
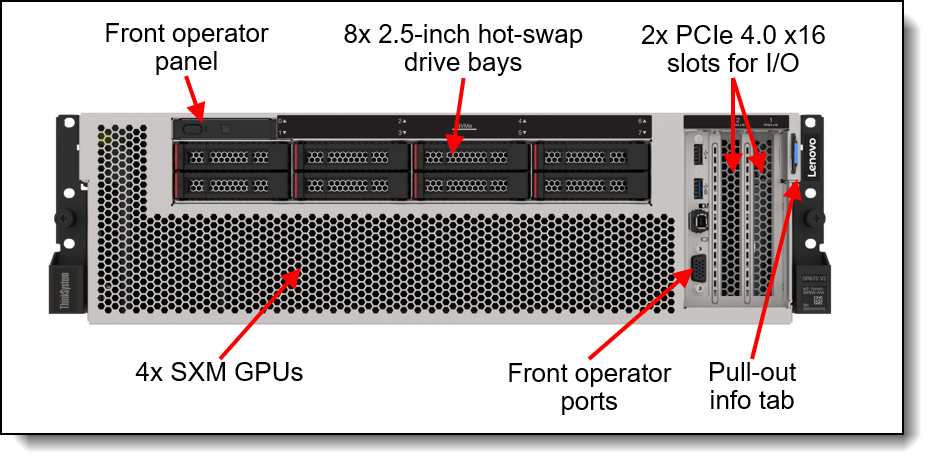
The accelerated module consists of eight server units each representing an accelerated compute node. The accelerated compute node is Lenovo ThinkSystem SR670 V2 a versatile GPU-rich 3U rack server equipped with the NVIDIA HGX A100 4-GPU set. All GPGPUs are symmetricaly connected with NVLink (i.e. equal badwidth between arbitrary pair of GPU accelerators). The server contains the same number and type of CPUs as the universal compute node. There are two groups of accelerated compute nodes that differ slightly in local storage performance.
Accelerated compute nodes deliver most of the compute power usable for HPC as well as excellent performance in HPDA and AI workloads, especially in the learning phase of Deep Neural Networks.
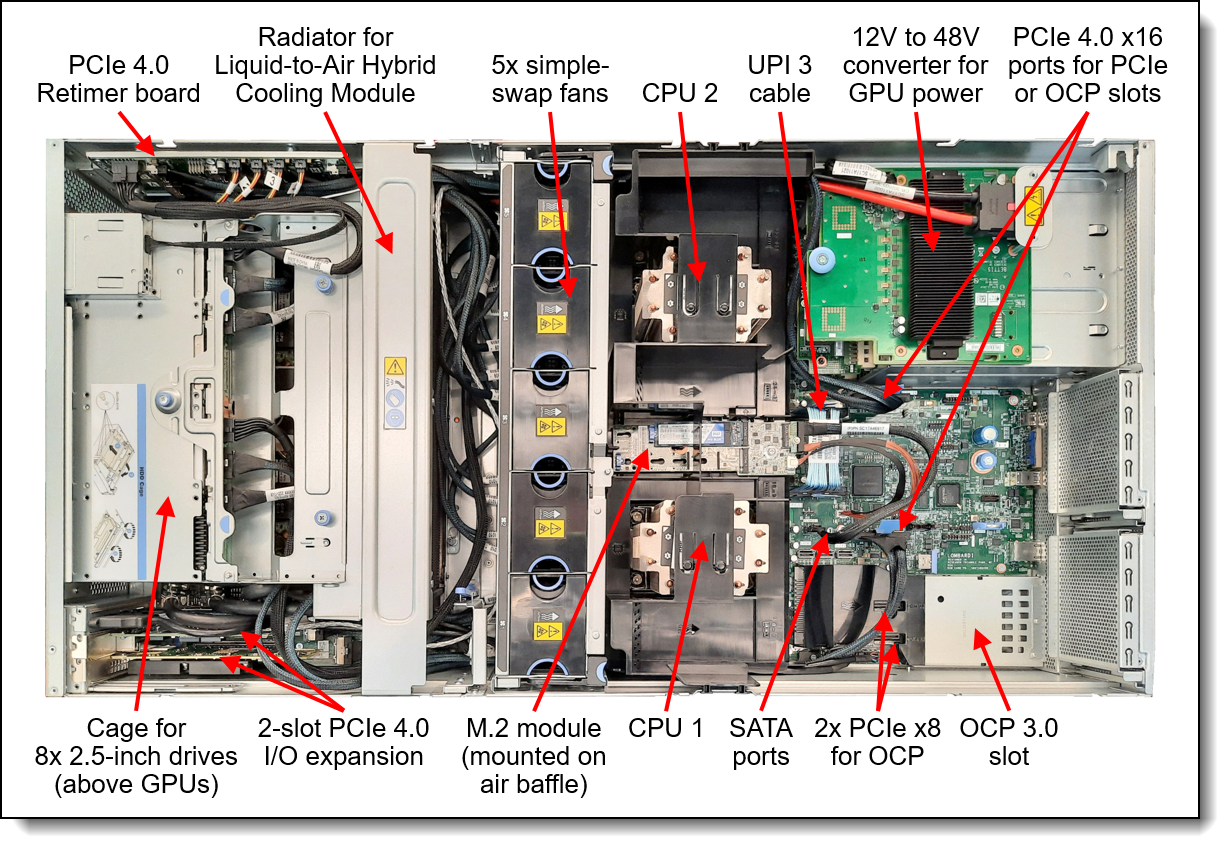

Accelerated compute node facts:
| Feature | n[141-144] | n[145-148] |
|---|---|---|
| Processora | 2× Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
| RAM | 256 GB DDR4 RAM @ 3200 MHz | |
| Diskb | 3.84 TB NVMe SSD @ 5.8 GB/s, 362 kIOPs | 3.84 TB NVMe SSD @ 2.3 GB/s, 166 kIOPs |
| GPGPU | 4× Nvidia A100 SXM4, 40 GB HBM2 | |
| Network | 200 Gb/s HDR Infiniband | |
| Performancec | ????? GFLOP/s per accelerated compute node | |
a 2.00GHz base, 3.2GHz single core.
b Performance data obtained with synthetic fio test. Bandwidth measured at mixed sequential read/write test (ratio 80/20 and 1M block). Operations count measured at mixed random read/write test (ratio 80/20 and 4k block).
c DP.
Processors¶
Intel® Xeon® Gold 6338¶
Intel® Xeon® Gold 6338 is a 64-bit 32-core x86 high-performance scalable server microprocessor that was designed to easily handle demanding workloads and complex tasks. The release date of the processor is Q2 2021 and is manufactured on with 10 nm technology. This microprocessor has 48 MB of L3 cache and supports up to 6 TB of DDR4-3200 memory (8 memory channels per CPU). Extended instruction set of the processor contains Intel® SSE4.2, Intel® AVX, Intel® AVX2, Intel® AVX-512.
Intel® Xeon® Gold 6338 facts:
| Intel® Xeon® Gold 6338 | |||
|---|---|---|---|
| Cores | 32 | Intel® UPI Speed | 11.2 GT/s |
| Threads | 64 | Memory | 6 TB @ DDR4-3200 |
| Base Frequency | 2.00 GHz | Process | 10 nm |
| Max Turbo Frequency | 3.20 GHZ | TDP | 205 W |
Accelerators¶
NVIDIA® A100¶
The NVIDIA® A100 Tensor Core GPU supports a broad range of math precisions, providing a single accelerator for multitude of workloads. A100 can efficiently scale up or be partitioned into seven isolated GPU instances, with Multi-Instance GPU (MIG) providing a unified platform that enables dynamical adjustment to shifting workload demands.
NVIDIA® A100 facts:
| NVIDIA® A100 | |||
|---|---|---|---|
| NVIDIA® Cuda Cores | 6912 | Single-Precision Performance | 19.5 TFLOP/s |
| NVIDIA® Tensor Cores | 432 | Double-Precision Performance | 9.7 TFLOP/s |
| GPU Memory | 40 GB HBM2 | Memory Bandwidth | 1555 GB/sec |
| System Interconnect | NVIDIA® NVLink | Interconnect Bandwidth | 600 GB/sec |